
Indice articolo
- 1 Installare tesseract-ocr e gImageReader
- 2 Importazione o acquisizione di foto o documenti in gImageReader
- 3 Acquisizione dallo scanner
- 4 Tipo di file da esportare dopo l'OCR
- 5 Riconoscimento automatico delle zone della pagina
- 6 Riconoscimento assistito del tipo di pagina
- 7 Indicazione della lingua o delle lingue nel documento
- 8 Analisi del testo
- 9 Riconoscimento OCR
- 10 Modifiche al testo in gImageReader
- 11 Salvataggio del risultato
OCR con Linux Mint? Certo. Potrà capitarti di frequente di aver bisogno di estrarre del testo da scansioni, da documenti pdf o immagini il cui testo non è selezionabile. Evitando di dover riscrivere di nuovo tutto il contenuto! Ecco come installare il motore di riconoscimento e un programma grafico. E come gestire tutto passo passo.
OCR con Linux Mint. Ovvero riconoscimento ottico dei caratteri da immagini, PDF, scansioni o altro. Da cui estrapolare il testo stampato per poterlo modificare senza doverlo digitare tutto? Possibile, open-source e gratuito.
Se hai esperienze precedenti con Windows avrai certamente avuto la possibilità di provare TextBridge o OmniPage. I rispettivi CD-Rom di installazione accompagnavano, in versione ridotta, molte stampanti multifunzione e scanner negli ultimi 20 anni..
Va però premesso che deve trattarsi di scansioni di qualità non inferiore a 300dpi, che non abbiano come fonte fax o fotocopie dalla qualità già ridotta. Inoltre deve trattarsi di testo stampato puro: eventuali annotazioni a mano sovrapposte al testo, rendono difficile il riconoscimento.
Per fare OCR con Linux Mint la soluzione free, nel senso duplice di libera e gratuita, si chiama tesseract-ocr.
O meglio, questo è il motore che sta dietro al meccanismo di riconoscimento ottico dei caratteri, Optical Character Recognition appunto.
Ma se non sei un guru di Linux hai bisogno anche di una interfaccia grafica tramite cui interagire.
Io consiglio gImageReader.

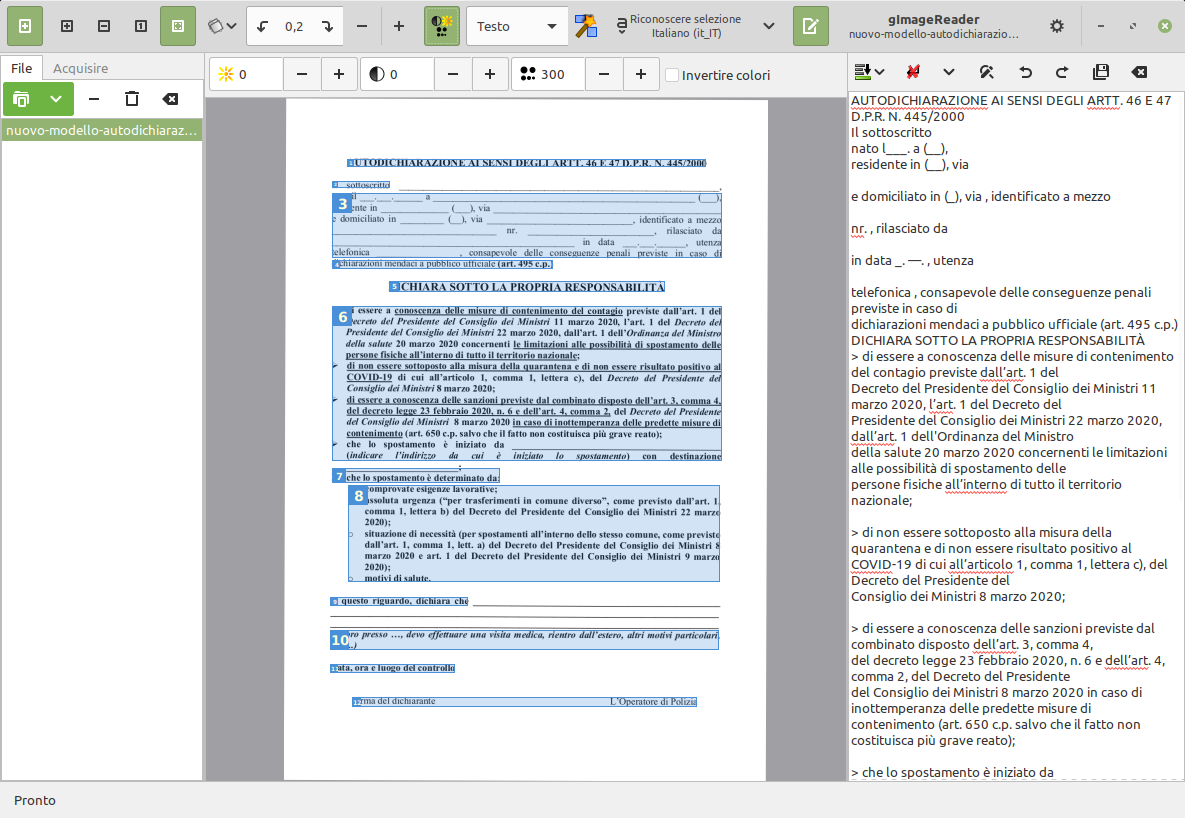
Trovi tutti i pacchetti che servono nel Gestore Applicazioni di Linux Mint e nel Software Center di Ubuntu.
Installare tesseract-ocr e gImageReader
Cominciamo proprio digitando nel campo di ricerca tesseract.
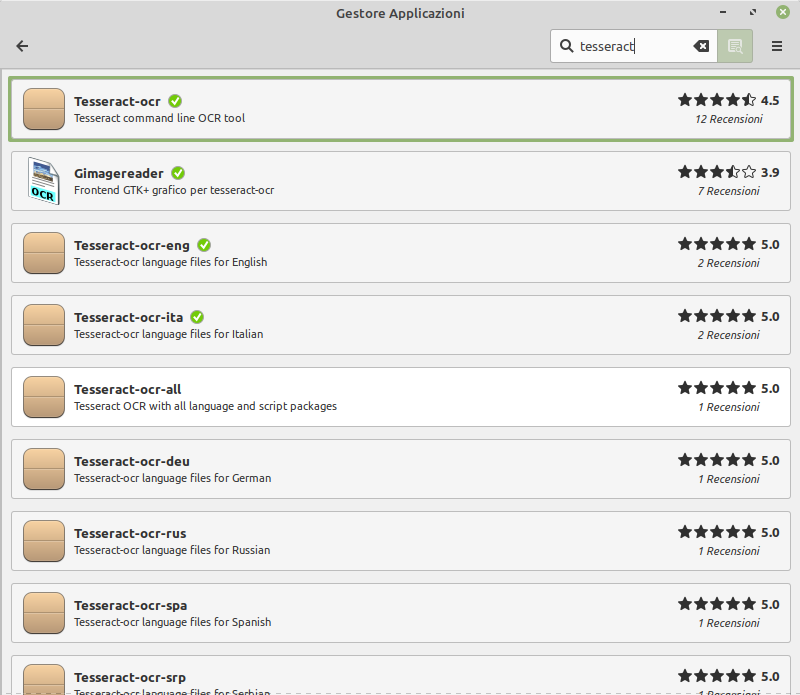
Non cambia molto l'ordine in cui procedi alle installazioni ma partirei comunque dal pacchetto tesseract-ocr.
Per poi aggiungere dizionari per l'italiano (tesseract-ocr-ita) e per lingue per le quali vuoi abilitare il controllo ortografico.
Oppure, se preferisci, puoi scaricare solo il pacchetto tesseract-ocr-all che incorpora tutte quelle supportate.
La ricerca per tesseract potrebbe mostrare anche gImageReader che installerei per ultimo. Anche lui è nel Gestore Applicazione se non vuoi cliccare il link xdg.
Importazione o acquisizione di foto o documenti in gImageReader
Installati i pacchetti, hai tutto quanto serva a fare OCR con Linux Mint.
Avvia gImageReader. Lo trovi aprendo il menu di Linux Mint e digitandone il nome oppure sotto la voce Grafica.
Nella finestra principale devi seguire un ordine di lettura e di interventi da sinistra verso destra.
In primo luogo, nella colonna più a sinistra, devi indicare a gImageReader se vuoi estrarre il testo da documenti o foto che già possiedi oppure se devi ancora acquisirli con lo scanner. Ma consente anche di fare screenshot da cui estrarre testo.
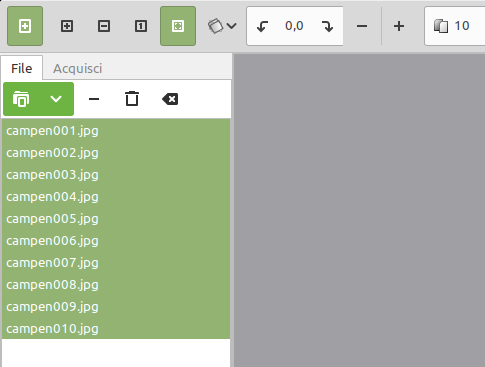
Nel primo caso, nella scheda File, premi sul pulsante verde per aggiungere i documenti. Molte sono le possibilità in questo senso quanto a tipi di file. Puoi aggiungere PDF, file di immagine, screenshots e incollare contenuti copiati in altra applicazione.
È infatti anche molto comodo ricorrere a gImageReader anche per unire più JPG o PNG e produrre un unico PDF.
Nella finestra che si apre, per indicare il percorso dei file, qualora siano multipli, puoi selezionare tutti quelli presenti in una cartella premendo la combinazione di tasti CTRL+A e poi cliccando su OK per importarli tutti.

Acquisizione dallo scanner
Nel secondo caso clicca sulla scheda Acquisire accanto a quella File e vedrai partire lo scanner. Puoi ancora impostare la risoluzione della scansione ed il percorso in cui il file verrà salvato.
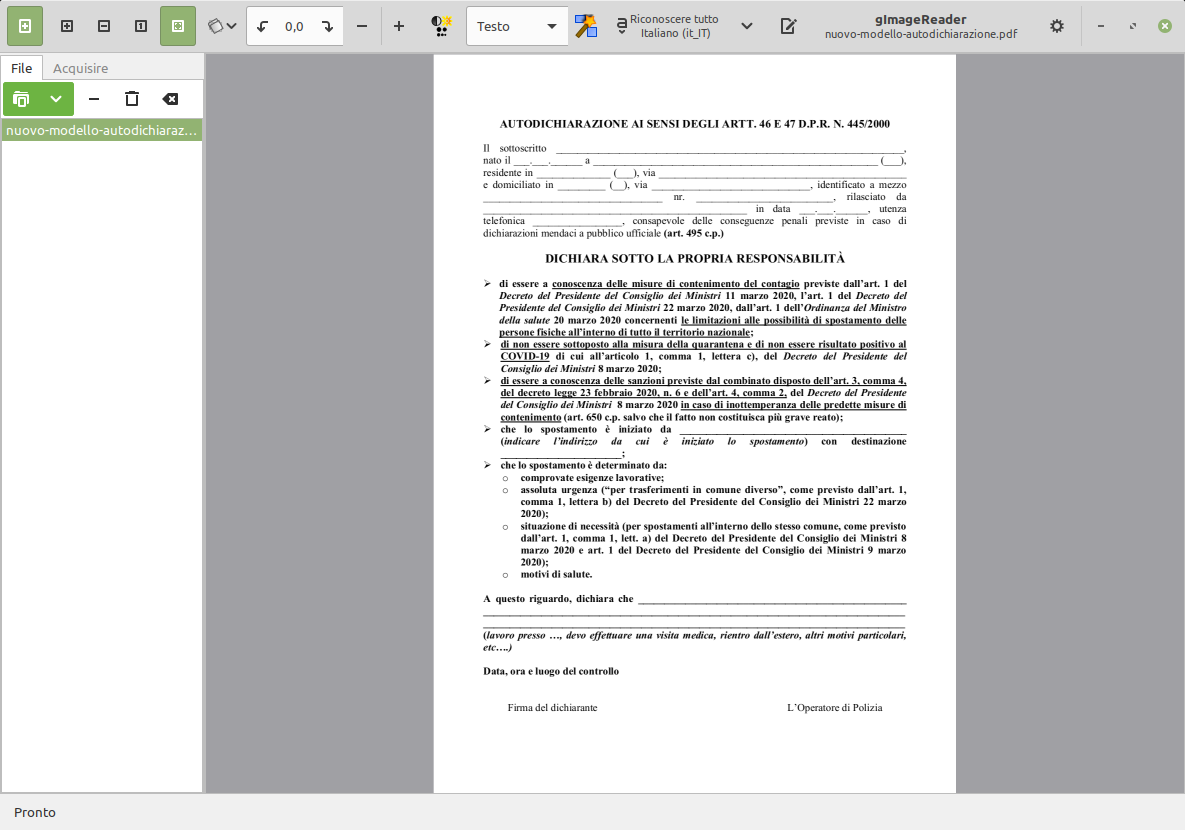
Con i primi pulsanti nella barra in alto a sinistra nell'interfaccia puoi eventualmente intervenire con lo zoom o per ruotare la pagina se necessario. Comunque gImageReader orienta alla perfezione automaticamente ogni pagina.

Tipo di file da esportare dopo l'OCR
Arriva il momento di indicare a gImageReader se vuoi che si limiti ad estrarre solo il testo dal documento oppure, se la sua struttura è complessa, a cercare di rispettarne l'impaginazione. Devi scegliere rispettivamente Testo oppure hOCR, PDF dall'elenco a discesa che si trova nella parte alta centrale dell'interfaccia.
Nel primo caso potrai fare un copia e incolla dal pannello anteprima o salvare ed esportare il testo riconosciuto in formato "puro".
Nel secondo caso verrà creata una specie di documento HTML, come una pagina web. Ma il risultato potrebbe non essere all'altezza delle aspettative o non meritare gli sforzi richiesti.
A meno che non sia indispensabile utilizzare il formato di interscambio hOCR con altre applicazioni.
Riconoscimento automatico delle zone della pagina
Nella modalità di esportazione Testo, seppure non indispensabile, è consigliabile premere dapprima il pulsante che si trova a destra del menu a discesa.
In modo da far analizzare preventivamente l'impaginazione del documento e una serie numerata di zone riconosciute nella pagina attuale.
Puoi ridimensionare ciascuna delle aree trascinandone i bordi. Oppure eliminarla cliccandoci con il pulsante destro e la relativa opzione.
Riconoscimento assistito del tipo di pagina
Se gImageReader non comprende la struttura di una pagina del tuo documento (brochure o contenuti misti testo, foto, tabelle), puoi assisterlo. Disattiva l'opzione di segmentazione automatica delle zone. Per poi indicargli, tra varie opzioni, la più adeguata per la pagina del documento attualmente selezionata.
Dopo i primi tentativi, consiglio di dedicare più tempo, se possibile, a questa fase. Talvolta infatti gImageReader finisce per identificare troppe zone e complicarsi la vita da solo.
Questa è infatti la fase principale per fare al meglio OCR con Linux Mint. E supportare al meglio il programma nel riconoscere le zone di testo per ogni pagina. Sempre che con la prima opzione il risultato non sia soddisfacente.
Clicca sulla freccetta verso il basso sul lato destro dell'elenco delle lingue.
Si apre il menu contestuale e una voce, Modalità di segmentazione della pagina, contiene varie opzioni. Le più importanti per un risultato adeguato.

Fornisci indicazioni più precise sul tipo di contenuto della pagina se in automatico gImageReader non fa un buon lavoro di riconoscimento delle zone.
Inoltre, se gImageReader non comprende la struttura di una pagina, puoi anche delimitare manualmente le differenti zone da riconoscere. Effettuando selezioni con click e trascinamento del mouse, il c.d. drag and drop. Puoi creare molteplici zone mantenendo premuto il tasto CTRL in aggiunta al trascinamento.
L'ordine numerico delle zone sarà quello che gImageReader seguirà per analisi e successivo riconoscimento.
Indicazione della lingua o delle lingue nel documento
Arriva il momento di selezionare, dall'apposito elenco più a destra, la lingua del documento. Servirà a gImageReader per sottolineare in rosso, nell'anteprima del testo riconosciuto, parole non presenti nel dizionario e semplificare l'identificazione di errori.
Seleziona la lingua cliccando sulla freccetta verso il basso sul lato destro dell'elenco. Si apre il menu contestuale.
Dal menu stavolta selezioni anzitutto se, nel documento da riconoscere, il testo è in una sola lingua o molteplici. Accorgimento utile nei casi di termini stranieri nel testo. E lo ripeto, solo ai fini della correzione ortografica e sottolineature in rosso di termini non conosciuti.

Analisi del testo
Nei casi di molteplici pagine o file da analizzare, l'analisi iniziale sulla struttura delle pagine può venire eseguita singolarmente per ciascuna di esse. Oppure per tutte (o una parte per volta) di quelle importate.
Selezioni una pagina alla volta da sottoporre ad analisi, nella colonna sinistra con i file importati, con un click. Selezioni più pagine cliccando e tenendo sempre premuto sulla tastiera il tasto CTRL.
Oppure, con la combinazione di tasti CTRL+A puoi selezionare tutti quelli importati.
Se sono selezionate più pagine, il programma consente di scegliere tra una analisi dell'impaginazione pagina per pagina o completa di tutte le pagine.
Se il computer non è molto potente o nuovo, in caso di documenti lunghi, procederei per step. Senza esagerare con il numero contemporaneo di pagine analizzate. Come la finestra del programma consiglia di fare quando avvii l'analisi multipagina.
Riconoscimento OCR
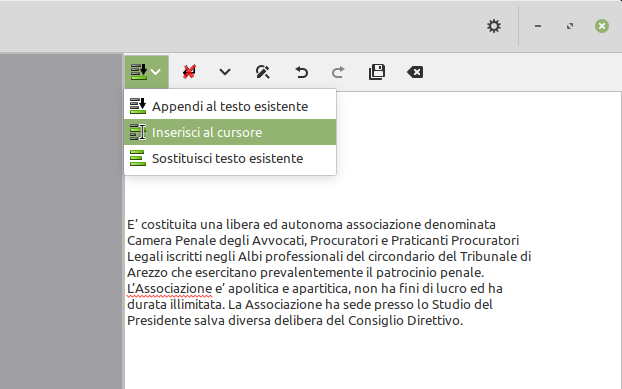
Terminata l'analisi di una o più pagine, se non hai selezionato le procedure multi-pagina, premi sul pulsante Riconoscere tutto per avviare il riconoscimento ottico dei caratteri.
Il testo riconosciuto viene visualizzato nel pannello di anteprima output più a destra, via via che il riconoscimento progredisce.
Se analizzi ed effettui il riconoscimento una pagina alla volta, il testo delle pagine riconosciute successivamente alla prima, sarà accodato al precedente nel pannello di anteprima del risultato.
Ma puoi anche posizionare il cursore in un punto preciso del testo. E istruire gImageReader a posizionare in quella posizione il nuovo testo.
Oppure, utile se devi effettuare molteplici analisi e riconoscimenti per una pagina complicata, puoi scegliere che il testo già presente venga sostituito dal nuovo.
Queste ultime opzioni le trovi premendo la freccia in basso a destra del primo dei pulsanti, nella piccola barra di icone nel pannello di anteprima del risultato./img

Modifiche al testo in gImageReader
Puoi effettuare diversi controlli o modifiche prima di esportare il testo. O fare un copia incolla dal pannello di anteprima risultato ad altro programma per l'impaginazione.
Si possono rimuovere spazi in eccesso o interruzioni di riga (a capo) dal testo già presente nel pannello. È il secondo pulsante da sinistra, con la x rossa.
Si possono effettuare ricerche e sostituzioni di caratteri o parole.
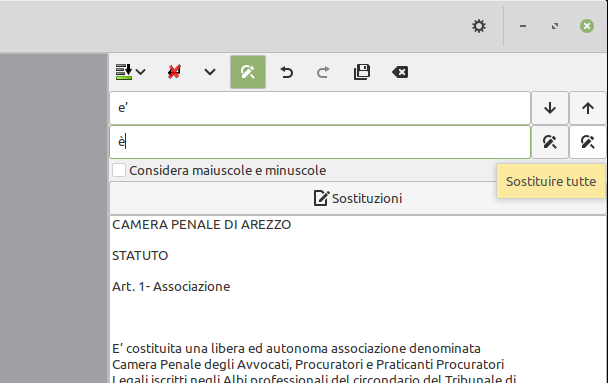
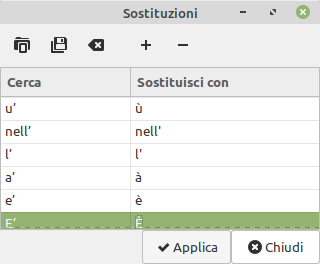
Non solo: può essere creato un elenco di sostituzioni da applicare al testo. Ecco a cosa serve il bottone Sostituzioni sotto i campi.
Un'apposita piccola finestra consente di aggiungere nuove regole di sostituzione, applicarle tutte al medesimo testo. E di esportarle in un file da reimportare per successive reinstallazioni.
Salvataggio del risultato
Puoi proseguire con il riconoscimento delle altre eventuali pagine e infine salvare il risultato cliccando sul pulsante a forma di floppy disk.
Grazie quindi ai progetti tesseract e gimagereader per l'OCR in Linux Mint. Tesseract non è un software infallibile ma non lo sono mai i programmi di OCR. E probabilmente, se hai precedente esperienza di software simili anche con Windows, lo avrai sperimentato. Molto dipende spesso anche dalla qualità delle scansioni che rendono il percorso più ostico.
Però questo genere di applicazioni si rivela comunque utile a risparmiare molto tempo. Anche se i risultati vanno ricontrollati con attenzione. Se poi è possibile farlo con programmi open-source e gratuiti ancora meglio.
Come fare OCR in linux Mint era originariamente parte della serie di tutorial nel post Usare Linux Mint per lavoro, poi integrato tanto da meritare un post apposito. Se non lo conosci, sappi che ci sono diversi altri aspetti interessanti.
E altrettanti video nel canale YouTube di alternativalinux e anzi, una specifica playlist di video su come usare Linux Mint per lavoro.
I video sono comunque incorporati nelle rispettive zone della guida qui nel blog.
Come al solito sei sempre preciso, pulito ordinato e chiaro nell’esposizione proprio come il nostro sistema operativo preferito 😉
Grazie per i tuoi preziosi lavori che condividi con noi perchè sono sicuro che servano a molti !!!
Continua così!
Un abbraccio da Palermo!
Grazie Mario! Tu, come al solito, scegli di fare apprezzamenti puntuali e graditissimi che mi confermano che sto andando nella direzione giusta!
Un abbraccio anche a te.
Dario
Ciao, ti rinnovo i complimenti per il tuo lavoro davvero interessante.
Approfitto di questo articolo per chiederti se esiste in programma ocr open source per linux che possa fare la scanzione a zone (come fa anche gimagereader) ma che posso lavorare in batch. Utilissimo, direi indispensabile, per estrarre solo una parte dei dati da scansioni di tanti documenti.
Grazie e avanti cosi.
Giampiero
Ciao Giampiero e grazie. Elaborazione batch credo potrebbe essere fatta da riga di comando con un “loop” e tesseract ma non con la selezione di zone se non l’indicazione generica del tipo di contenuto come nel menu di gimagereader. A me verrebbe in mente che si potrebbe mescolare imagemagick con tesseract per fare ciò che dici ma andrebbe realizzato apposito programma… Oppure ho trovato https://sourceforge.net/projects/vietocr/
Un altro programma che consiglio di avere è OCRFeeder che esporta il file in odt 🙂
Grazie Paolo! In effetti OCRFeeder merita di essere citato anche più di gImageReader!