
Indice articolo
- 1 SpeechNote: riconoscimento vocale, sintesi traduttore Linux
- 2 Installazione di SpeechNote
- 3 Scaricamento di modelli linguistici
- 4 Blocco note: per riconoscimento vocale e sintesi vocale in Linux
- 5 Sintesi vocale (Text To Speech) ed esportazione di file audio
- 6 Clonazione della voce
- 7 Traduttore
- 8 Riassumendo...
Riconoscimento, sintesi vocale e traduttore per Linux. SpeechNote, mirabile software open-source e gratuito per Linux. Integra funzionalità di dettatura accurata senza necessità addestramento, sintesi vocale e clonazione della propria voce con esportazione audio e infine traduzione simultanea. Il tutto in tantissime lingue, senza connessione internet e quindi con i massimi livelli di privacy. Vediamolo insieme.
SpeechNote: riconoscimento vocale, sintesi traduttore Linux
Pochi giorni fa, esplorando Gestore Applicazioni, l'app store di Linux Mint, ho scoperto SpeechNote. Un programma dotato di interfaccia grafica che promette grandi cose. Ho trovato SpeechNote tra i Flatpak di Flathub anche se scopro che esiste una versione scaricabile da GitHub per Arch Linux e derivate che attualmente ha nome DSNote.
Su Flathub leggo in inglese una descrizione in inglese di cui riporto, di seguito, la traduzione italiana ottenuta dal software stesso: "SpeechNote ti consente di prendere, leggere e tradurre note in più lingue. Utilizza Speech to Text, Text to Speech e Translation Machine per farlo. L'elaborazione del testo e della voce avviene interamente offline, localmente sul computer, senza utilizzare una connessione di rete. La tua privacy è sempre rispettata. Nessun dato viene inviato a Internet".

Installazione di SpeechNote
Puoi installarlo anche tu con un click, come ho già fatto io, se il centro software della tua distro prevede i flatpak. Se il tuo OS è su base Arch Linux potrai compilarlo ed installarlo dai sorgenti.
Al momento, la versione 4.4 in flatpak, richiede lo scaricamento di circa 900 MB di dati e va ad occupare circa 3 GB di spazio su disco. Non sono eccessivi se pensi che hai in un solo programma riconoscimento vocale sintesi traduttore Linux Se hai una scheda grafica dedicata, a questi sarebbe bene aggiungere c.d. addon previsti per NVIDIA o AMD per sfruttarne l'accelerazione hardware. Il programma può risultare impegnativo in certi compiti, con alcuni profili di riconoscimento o sintesi vocale.
Se non trovi gli addon nel centro software, puoi installarli da terminale rispettivamente con i comandi:
flatpak install net.mkiol.SpeechNote.Addon.nvidia
flatpak install net.mkiol.SpeechNote.Addon.amd
Ma ti avviso che richiedono rispettivamente lo scaricamento di 7 GB e 4 GB di dati per uno spazio finale richiesto su disco di 7 e 12 GB.
Questa quantità di dati può certo scoraggiare ed è quindi prevista una versione alleggerita di molte librerie e quindi di funzionalità, con un pacchetto Tiny, definito quindi minuscolo, che puoi scaricare in flatpak da Github. A questo pacchetto possono comunque essere associati gli addon per schede grafiche.
Posiziona il file nella tua home, apri il terminale e digita flatpak install dsnote e premi il tasto [TAB] sulla tastiera per completare il nome file. Non servono privilegi sudo. Al momento della pubblicazione la versione del file è la seguente, ma quando lo installi potrebbe differire
flatpak install dsnote-4.4.0-x86_64-tiny.flatpak
Scaricamento di modelli linguistici
Il primo avvio di SpeechNote impone di selezionare e scaricare profili di riconoscimento vocale, di sintesi vocale e di traduzione per le lingue che ti interessano. E c'è da sbizzarrirsi. Per ognuno di essi è richiesto di scaricare ulteriori dati.
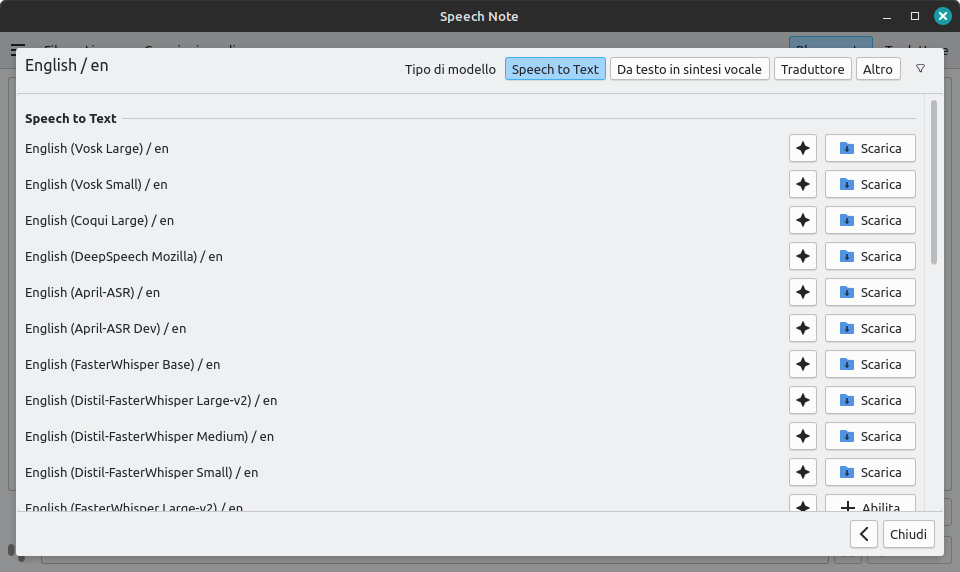
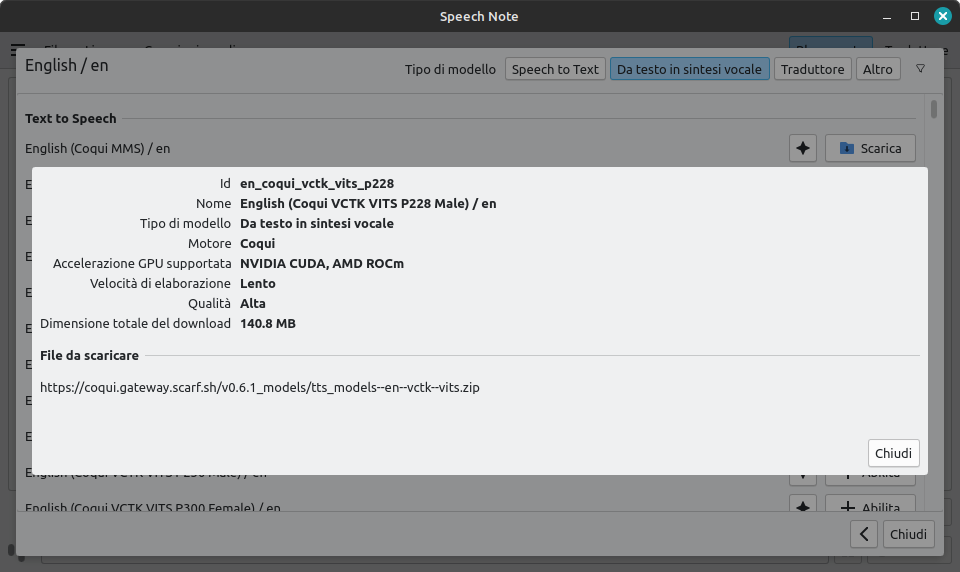
Conviene verificare anzitutto la qualità ed i tempi di elaborazione, evitando quelli più lenti nei computer non performanti. È assai consigliato scaricare anche i modelli di punteggiatura se usi un modello linguistico come quelli Whisper e FasterWhisper che la supportano come funzionalità aggiuntiva.
In linea generale i modelli Coqui, Whisper e FasterWhisper sono i migliori ma i più impegnativi. Quelli Mimic e Piper offrono buoni compromessi. Sono purtroppo attualmente scarsi, e non è colpa di SpeechNote, i modelli Espeak e tutti quelli di traduzione.
Blocco note: per riconoscimento vocale e sintesi vocale in Linux
Completato il download dei modelli, si passa alla scheda Blocco note. Sia per il riconoscimento vocale (Speech To Text) che per la sintesi vocale (Text To Speech, spesso abbreviato in TTS).
Riconoscimento vocale (speech to text)
Il modello Vosk Large è un buon compromesso per il riconoscimento vocale della lingua italiana. Quelli FasterWhisper e Whisper sono molto impegnativi per le risorse del computer ma supportano la punteggiatura. Questo significa che il modello linguistico, sulla base della inflessione della voce, è in grado di applicare automaticamente virgole, punti, punti esclamativi e punti interrogativi! Impressionante.
Nemmeno Dragon Naturally Speaking di Nuance ricordavo lo prevedesse quando ancora usavo Windows! E SpeechNote è certamente tra le valide alternative per questo software, anche se solo per gli utenti Linux.
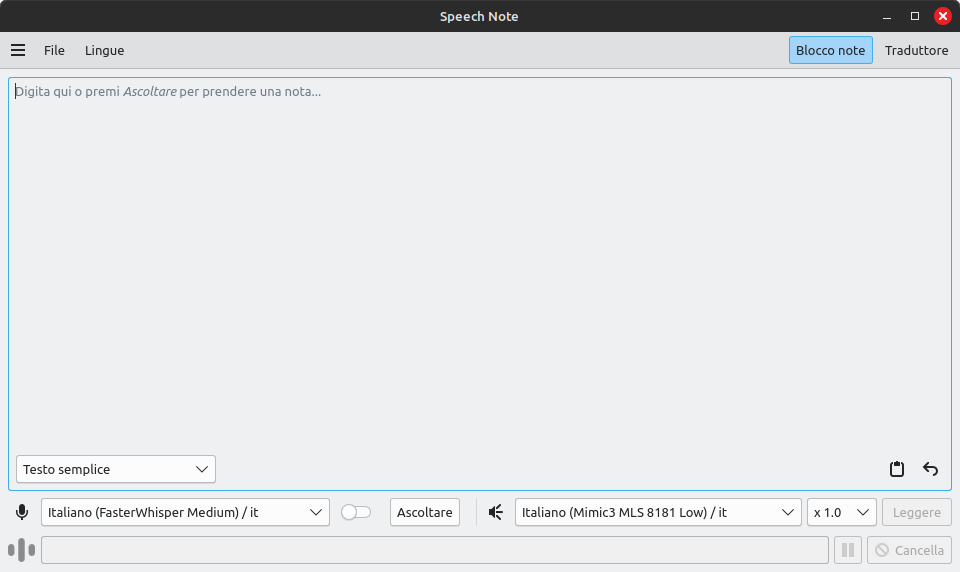
Selezionato il modello da usare per il riconoscimento, dall'apposito elenco a discesa sul lato inferiore sinistro della finestra, la pressione sul tasto Ascoltare, dà il via alla messa in ascolto. Per impostazione predefinita SpeechNote effettua l'elaborazione al termine di una frase, non appena rileva uno spazio di silenzio.
Questa impostazione può venire modificata nelle impostazioni di Speech to Text raggiungibili dal menu principale.
Se hai integrato modelli di traduzione dall'italiano, puoi addirittura attivare l'interruttore per la traduzione in modo che il risultato dell'ascolto sia scritto già nella lingua di destinazione.

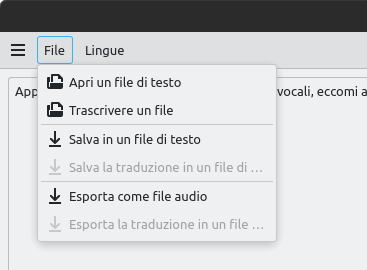
per importazione ed esportazione
Una volta completato il riconoscimento, dal menu File è possibile esportare il testo anche senza effettuare un copia e incolla, funzioni per le quali sono comunque previsti appositi tasti al di sotto dell'area di testo.
Trascrizione di file audio (sbobinamento) ed esportazione del testo
Sempre nella scheda Blocco Note, dal menu File, è possibile avviare la trascrizione di testo a partire dall'ascolto di un file audio o anche video.
nel riconoscimento vocale da file video
Questa funzione è assai utile per un riconoscimento vocale successivo. Devo dire di aver provato questa funzione con i modelli di lingua che supportano la punteggiatura automatica e i risultati sono sorprendenti! Ma ripeto che solo PC performanti e accelerazione GPU permettono di sfruttare seriamente questa caratteristica.
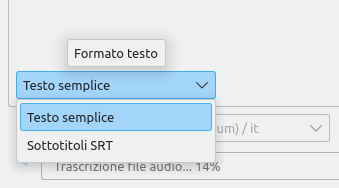
Se l'intenzione è quella di sottotitolare un video, allora si può intervenire nell'elenco a discesa Testo semplice, impostando l'opzione Sottotitoli SRT.
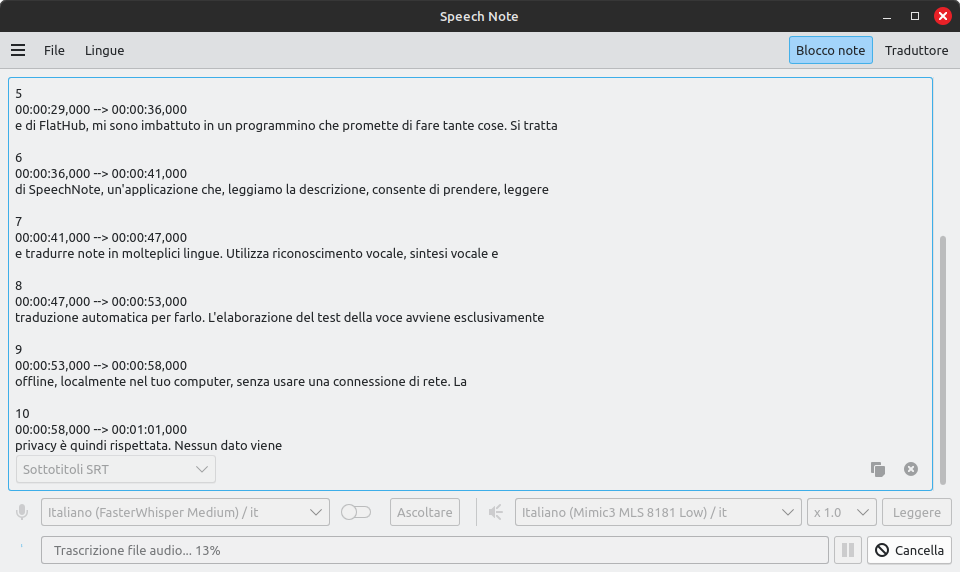
In questo caso il programma restituirà un formato standard compatibile con una vasta gamma di editor video, in modo da aggiungere sottotitoli sincronizzati al parlato nel video. Ancora eccezionale!
Sintesi vocale (Text To Speech) ed esportazione di file audio
È sempre dalla scheda Blocco Note che si provvede a caricare un file di testo o a digitare, oppure incollare, un testo già esistente, al fine di trasformarlo in parlato naturale. Per queste opzioni si seleziona il modello linguistico dall'elenco a discesa posto sulla destra e si può anche modificare la velocità del parlato rispetto a quella prevista da ogni singolo modello.
Come intuibile, con la pressione del tasto Leggere, si avvia l'elaborazione dello scritto e la trasformazione in parlato. Questa può richiedere più o meno tempo a seconda del modello linguistico e delle caratteristiche del computer.
Io ritengo possa risultare molto utile la sintesi vocale di una traduzione o un testo in lingua straniera, per migliorare la propria pronuncia.
Dal menu File è anche possibile esportare direttamente un file audio in formato MP3, Wave o altri, che viene creato sulla base delle impostazioni del modello e della velocità impostata.
Clonazione della voce
Il ricorso ad uno dei modelli di sintesi vocale Coqui XTTS, permette di sfruttare le ultime novità nel campo della clonazione vocale assistita da intelligenza artificiale. E questo significa che, con un campione audio adeguato, è possibile trasformare un testo in audio clonando la voce di un soggetto. Che può poi leggere un testo, non solo nella propria lingua, ma anche in lingue straniere.
Nel momento in cui si selezioni uno dei modelli di sintesi Coqui XTTS, la finestra principale di SpeechNote mostra una nuova voce di menu: Campioni vocali. L'accesso alla sezione consente di caricare un file audio o registrare un campione vocale attraverso il microfono.
La documentazione ufficiale di XTTS riferisce che sia sufficiente un campione di circa 6 secondi per ottenere risultati eccellenti.
Ho effettuato pochi test di queste funzioni a dire il vero. E senza ottenere risultati convincenti. La mancanza di documentazione su questa funzione di SpeechNote non mi consente di verificare come mai il risultato si discosti così tanto dagli ottimi risultati che trovo in rete, ottenuti addestrando XTTS da riga di comando.
Traduttore
Se dalla scheda Blocco note ci si sposta su quella Traduttore, le aree di testo diventano due: quella a sinistra per il testo da tradurre e quella destra per la traduzione. Per ognuna è ovviamente prevista la selezione della lingua di partenza e di destinazione oltre ai relativi modelli linguistici.
Per impostazione predefinita, la traduzione avviene durante la digitazione o non appena si incolla un testo.
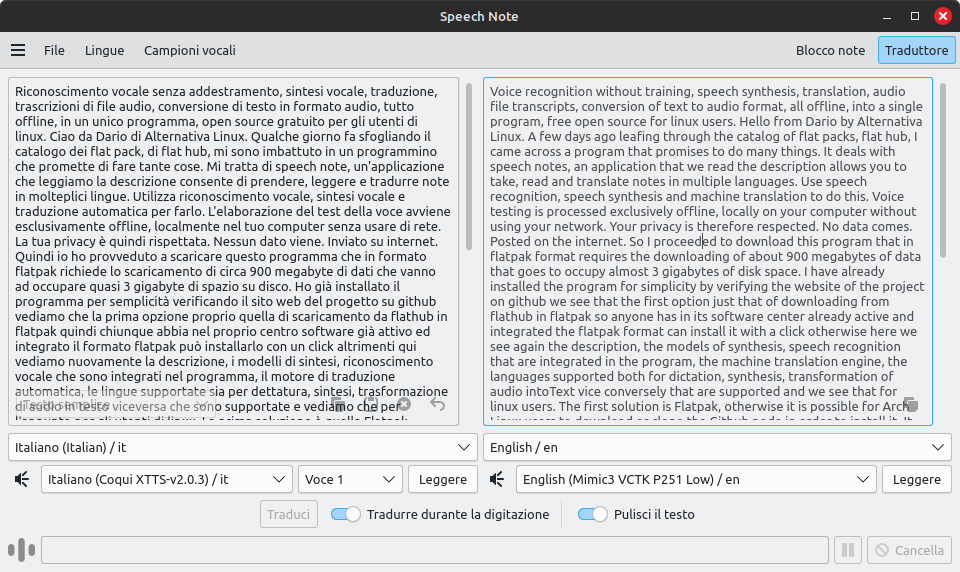
Purtroppo, come anticipato, al momento i modelli di traduzione che SpeechNote affida al motore Bergamot, sono molto limitati ed effettuano una traduzione meccanica, parola per parola, che può stravolgere il senso nella lingua di destinazione. Con un risultato assai poco professionale, come quello di certe email di spam la cui traduzione in italiano finisce per essere addirittura divertente.
Se questo rappresenta un limite per il programma di riconoscimento vocale, sintesi, traduttore Linux, non è certo per demerito di chi lo sviluppa.
C'è senza altro da augurarsi che modelli di traduzione più avanzati, magari basati su intelligenza artificiale, siano resi disponibili in formato aperto. Perché sono certo che SpeechNote li integrerebbe. E allora non ce ne sarebbe più per nessun altro servizio online o software, nemmeno a pagamento.
Riassumendo...
SpeechNote è una novità del panorama Linux ed integra funzioni di riconoscimento vocale, sintesi, traduttore, in unico software. Che, una volta scaricati modelli linguistici, non ha bisogno di connessione internet per svolgere egregiamente, con i modelli linguistici adeguati, questi compiti.
Le possibilità di trasformare in testo registrazioni audio o tracce sonore di un video, di esportare come audio testi e documenti, permettono di sfruttarlo a fondo in tutte le lingue desiderate.
Al momento i migliori profili di lingua, sia per il riconoscimento che per la conversione in parlato naturale, sono impegnativi per il computer. Ma ci sono molti profili che permettono ottimi risultati con minore potenza del computer. Oppure ricorrendo alla versione minimizzata di SpeechNote.
Nota dolente, al momento e si spera per poco, è la qualità delle traduzioni. Che non dipende da SpeechNote ma dall'unico modello che il software integra, Bergamot, che non si rivela adeguato alla competizione con le più recenti conquiste assistite da intelligenza artificicale.
Una volta che questo limite sia superato, SpeechNote potrebbe non avere rivali per quantità di funzioni, per la gratuità, e per la capacità di lavorare esclusivamente offline, senza connessione internet. Senza ricorrere a servizi di grandi aziende che non eliminerebbero mai informazioni e i nostri profili vocali, con le gigantesche implicazioni sulla privacy. Libertà questa cui pare ormai in tanti abbiano rinunciato.
Se il software ti interessa e ti risulta utile, prendi in considerazione l'idea di supportare lo sviluppatore che vi dedica tempo. Non è indispensabile fare una donazione tramite LiberaPay. Lascia una recensione al programma su Flathub o tramite il centro software da cui lo hai scaricato e informa altre persone. Rendiamo migliore il programma e rendiamo migliore il versante libero del software, anche di livello professionale.
ciao Dario sono franco B. mi permetto di suggerirti whisper per il riconoscimento vocale e la trascrizione del parlato in testo con tempi inferiori alla durata del file audio (sarebbe una manna per gli universitari ) .
Lo proverei io stesso su una macchina virtuale , ma per lavoro non mi rimane molto tempo
Conoscendo la serietà che metti nel tuo lavoro e vedendo l’espressione che hai fatto quando hai provato Speech Note (non sembravi soddisfatto) ho pensato di scriverti
Non so se è corretto citare altri siti per dare informazioni in più ma mi sono imbattuto per caso in questo sito e quindi te lo invio
https://www.laseroffice.it/blog/2022/09/27/whisper-un-software-open-source-per-il-riconoscimento-vocale-anche-per-litaliano/
Spero di fare cosa gradita
Ciao
Ciao Franco e grazie per la segnalazione che gradisco. Nel mio video ho espresso dubbi sulla clonazione della voce ma di certo non sui modelli Whisper e su Speechnote. Avevo sbagliato ad isolare il campione vocale nel video. Poi ho capito come fare, ma ribadisco che la clonazione non restituisce risultati interessanti.
Ma confermo la validità delle trascrizioni che con SpeechNote ho cominciato ad usare spesso e con il mio PC richiedono un decimo del tempo necessario ad ascoltare i file. E confermo pure che l’installazione con un clic di SpeechNote consenta di evitare tutti i passaggi descritti nella guida che mi sottoponi.
Nel frattempo lo sviluppatore sta per pubblicare la versione 4.5 come stabile e ci saranno interessanti novità. Ciao.
provando ad installare la versione tiny su ubuntu 22.04 con LXQT con i comandi che hai messo da errore ‘requires the runtime org.kde.Platform/x86_64/5.15-22.08 which was non found’. a te non succede perchè hai KDE? tnx
Ciao, è più parente di KDE Lxqt che Cinnamon. Non è quello il problema e io non ho mai provato ad installare flatpak fuori da flathub. Pare ti manchi la piattaforma KDE nella versione indicata. Prova ad installare con flatpak install org.kde.Platform